

AI 泡沫 “原罪”:英伟达是 AI 戒不掉的 “金毒丸”?
以 2022 年年末 ChatGPT 发布为标志,三年间 AI 狂热从算力、存储、网络、制造、电力基建、软件应用,甚至到边缘设备,每个方向的细分赛道都被轮番反复炒作了一遍。
但到三周年末,当 AI 基建的顶梁柱们,在三季报前后一个个宣布前所未有的 AI 大基建时,市场反而跟突然丧魂了一样,开始担心 AI 投资要泡沫了。
产业有人赚得盆满钵满,有人亏到疯狂融资,问题到底出在哪里?融资眼花缭乱,千奇百怪,为什么?
本篇,海豚君通过产业链核心公司的报表来仔细研究一下这些问题,并尝试理解,到底 AI 投资是否已经真走到泡沫阶段了?如果真有泡沫,那么泡沫的原罪在哪里?
一、融资眼花缭乱?产业链利润分配重度扭曲
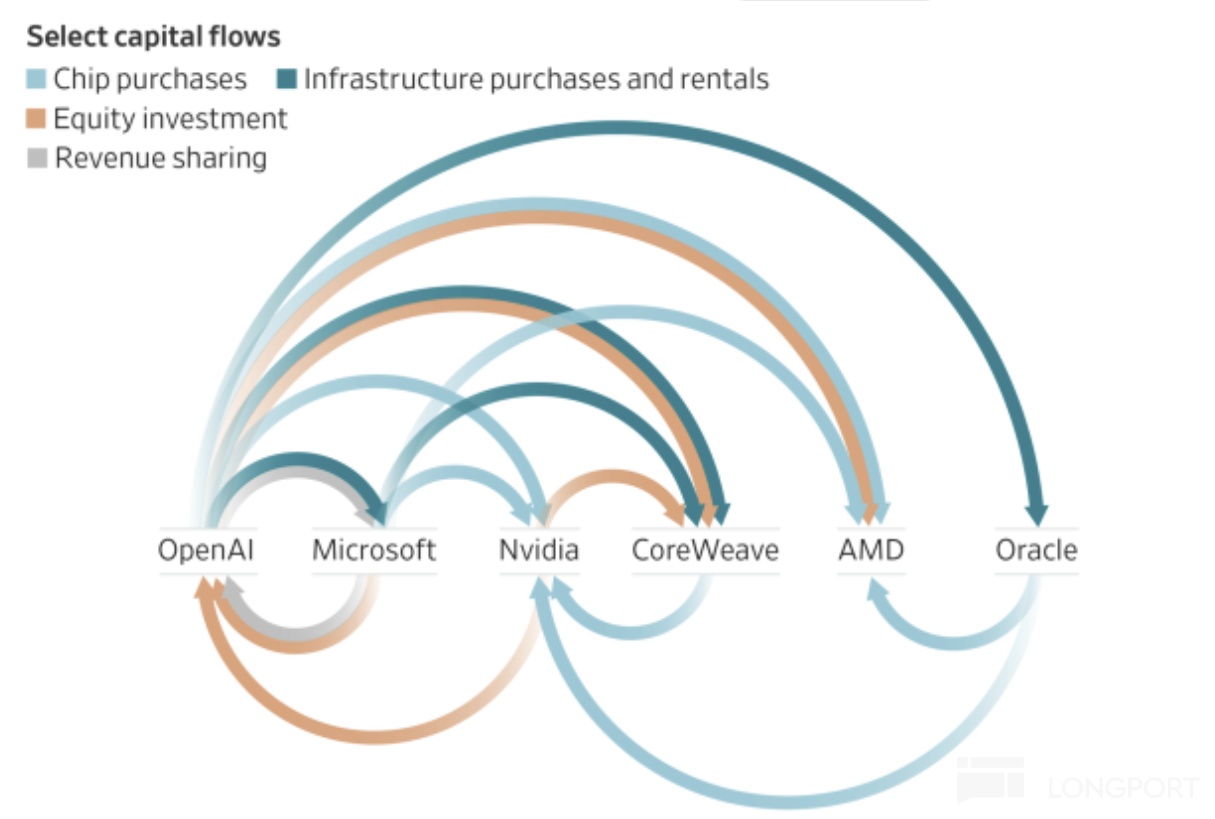
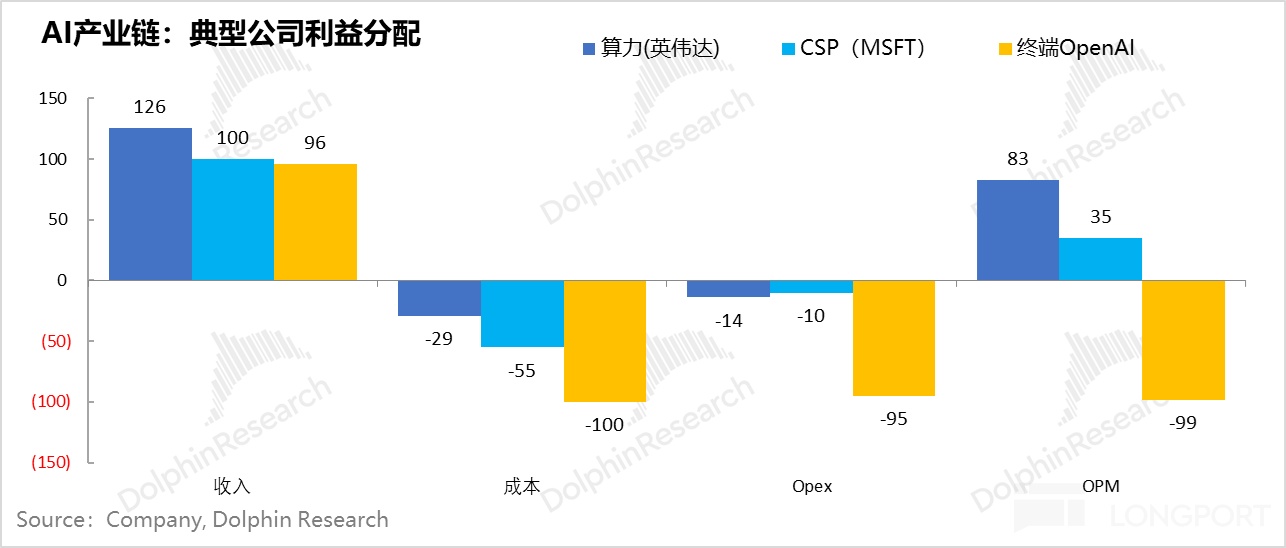
下面这张图,对很多人来说恐怕已经很熟悉了。这张图最大的问题,整个产业链的最终用户,也就是 OpenAI 的用户在整个资金循环链条里创收规模相比投入太小,没有被画到图中。
但张图的核心信息,其实也就是下游客户用上游供应链的钱来为自己的业务融资,这么一个简单而又古老的供应链融资方法。
同时,一级市场模型巨头们供应链融资同步发生的,还是二级市场应用巨头们已逐步普遍表内、表外债券融资(详细分析见此处)
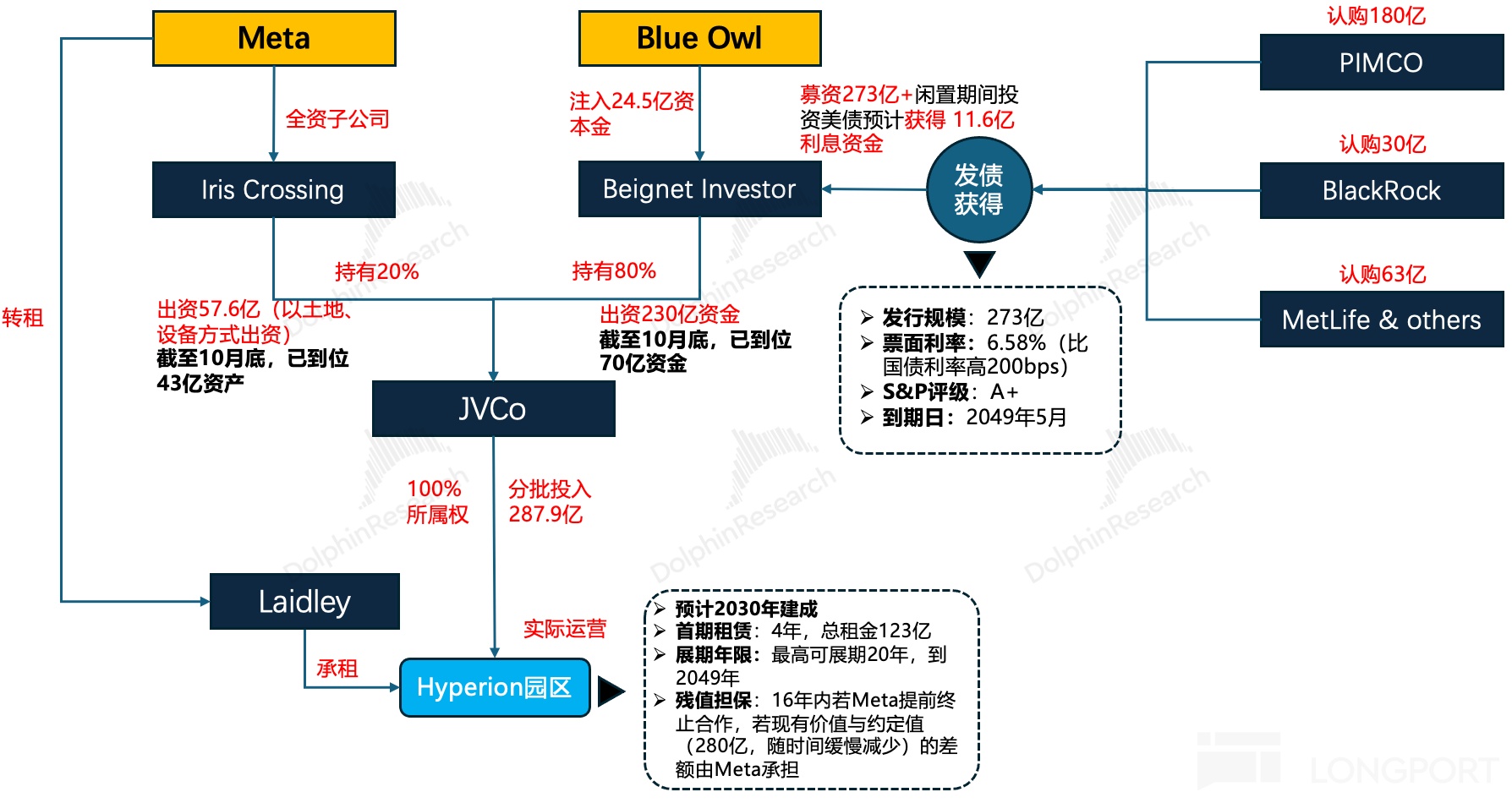
但这里的问题是,为何在芯片商如英伟达赚到盆满钵满、全市场都在说 AI 是新一场技术革命的时候,AI 拓荒人 OpenAI 要用下一盘这么大的融资棋局?为什么本来富到流油的美股巨头如$谷歌-A(GOOGL.US) 、Meta 等等,现在要用债务才能支撑未来的发展?
其实答案很简单,AI 产业初期,产业链利润分配重度不均,上游把好处基本“吃干抹净”了。
AI 的主产业链主要是这么五类玩家:晶圆代工($台积电(TSM.US) )——算力商($英伟达(NVDA.US) )——云服务商($微软(MSFT.US) )——模型商(OpenAI)——终端场景五层来分。
1.1)从云服务商的经济账说起:到底谁赚了红利、谁赚了吆喝、谁担了风险?
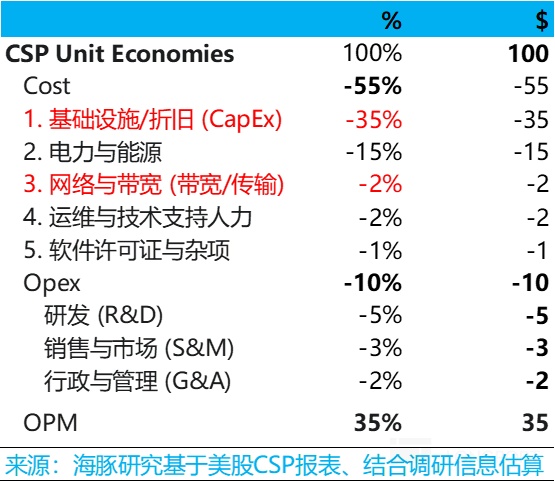
A. 云服务商们的经济账:100 元收入分布——55 元成本、10 元运营开支,35 元利润;
以下,海豚君用一本产业链一本简单的经济账来给大家仔细算下数,来直观了感受一下这场三年的 AI 繁荣当中。我们知道,云服务是一个既重资金壁垒,又重基本壁垒的行业。它的前半部分跟盖房子一样,需要把厂房盖起来、机柜、布线、冷却等等都要做好,这部分算是机房的硬装。
软装部分就是放入 GPU、CPU,这中间 GPU 内部的连接、GPU 与 GPU,以及与其他设备的连接要做好,再加上网络、宽带,通上电,软装基本完成。这些要素放在一起,再通过技术人员完成 “灵魂点睛”,就是一个比肩基础的 IaaS 服务了。
从上面的要素其实可以看出,虽然它听起来高大上,本质上没有摆脱运营商生意的范畴——把各种重资产 + 技术组合在一起,形成云服务,通过租赁云服务赚钱。
这个生意的核心就是,成本要足够低,比如说成本最高的 GPU 装上去了之后可以用个十年八载的,不能像光伏电场那样,隔三差五光伏板就要换掉。
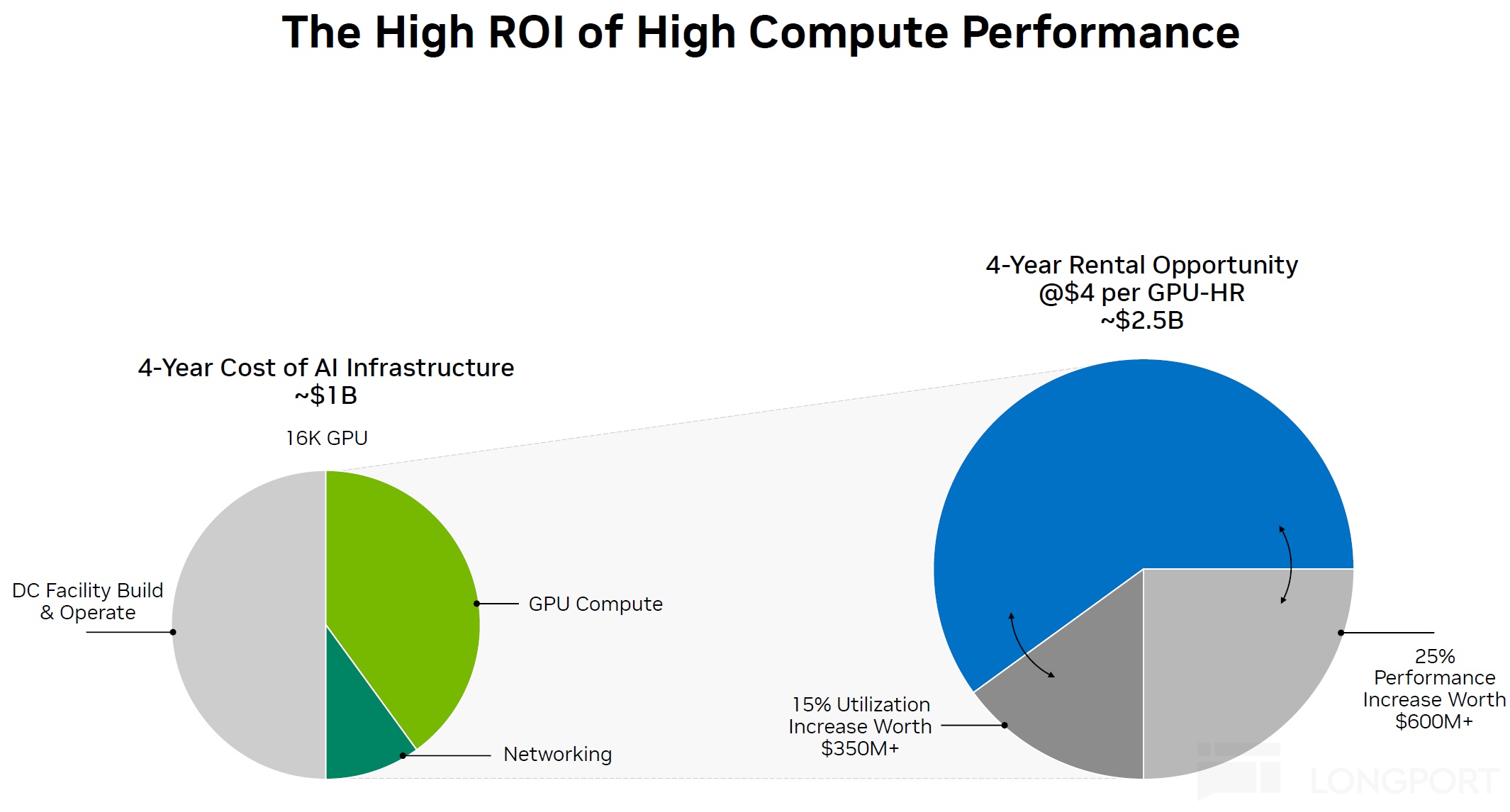
来源:英伟达 NDR 材料
按海豚君的估算,云服务商假如用全新的 AI 产能来提供 AI 云服务,那么每赚 100 元,大约 35 元是前期买入设备(以 GPU)的摊销折旧,GPU 折旧年限以目前云服务商普遍的五年期来算,资本开支投入其实是 175 元。
而如果英伟达的 GPU,那么基本上 125 元(70% 以上)是 GPU(含网络设备)提供生的收入,剩下是 CPU、存储、网络设备等。
除了固定成本,还有能源电力、带宽、运维等成本,而运营费用上,主要就是研发销售和行政等费用了。100 元的收入最终实现的账面经营利润是 35 元。
备注:数据取 AWS 和 Azure 中间值利润率估算,结合 GPU 云租赁的 ROI 与传统对比来做模拟
从这些数中,可以看到一个很明显的问题是:
① AI 基建早期,云服务商只有明面利润,实际严重缺钱:在这个简单的模型中,云服务商明面上是赚了 35 块钱,但由于其实在拿到收入之前,其实已经提前预支自己的全部 100 元收入都不够,需要花 175 元来先买 GPU 设备。也就是说 CSP 其实只赚了账面利润,实际投入是倒贴的。
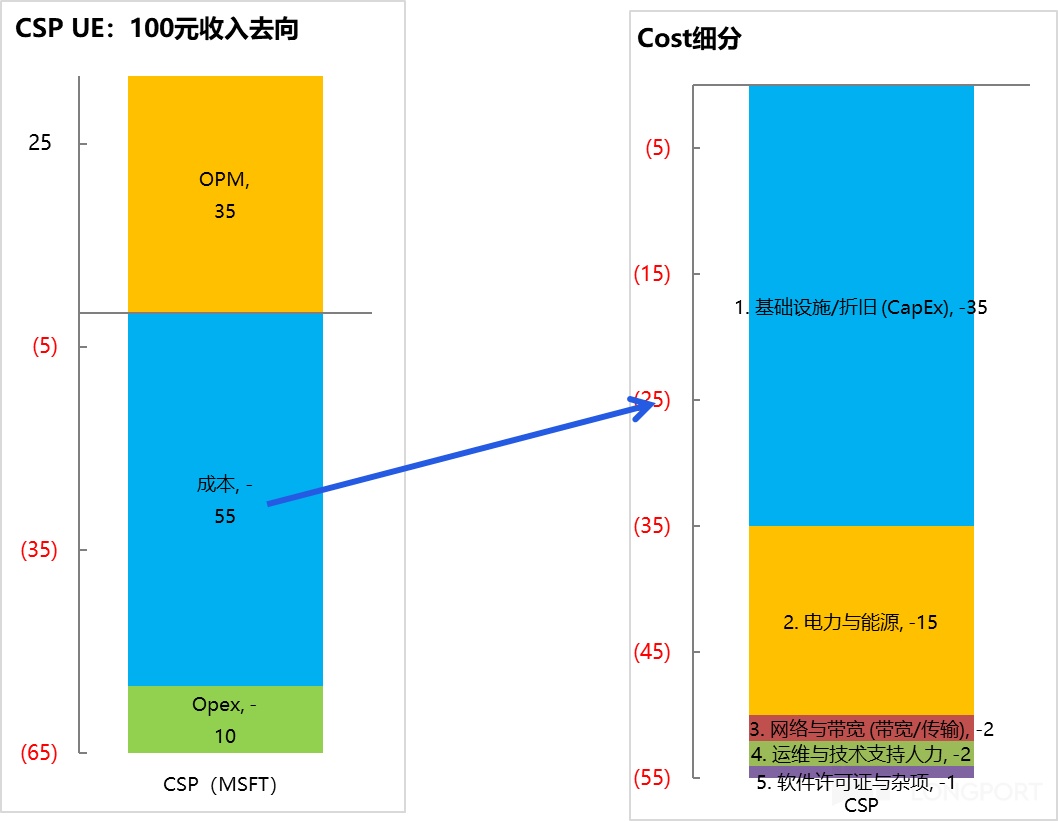
② 数据中心疯狂融资:云大厂由原本的现金牛业务来支撑,但现在新兴的新云如 CoreWeave、Nebius、Crusoe、Together、Lambda、Firmus 和 Nscale 等因为没有原本的现金流业务,现在普遍需要发行资产抵押支持证券融资来提供云服务。
B. 100 元的云服务收入,如何流入英伟达、OpenAI 账本?
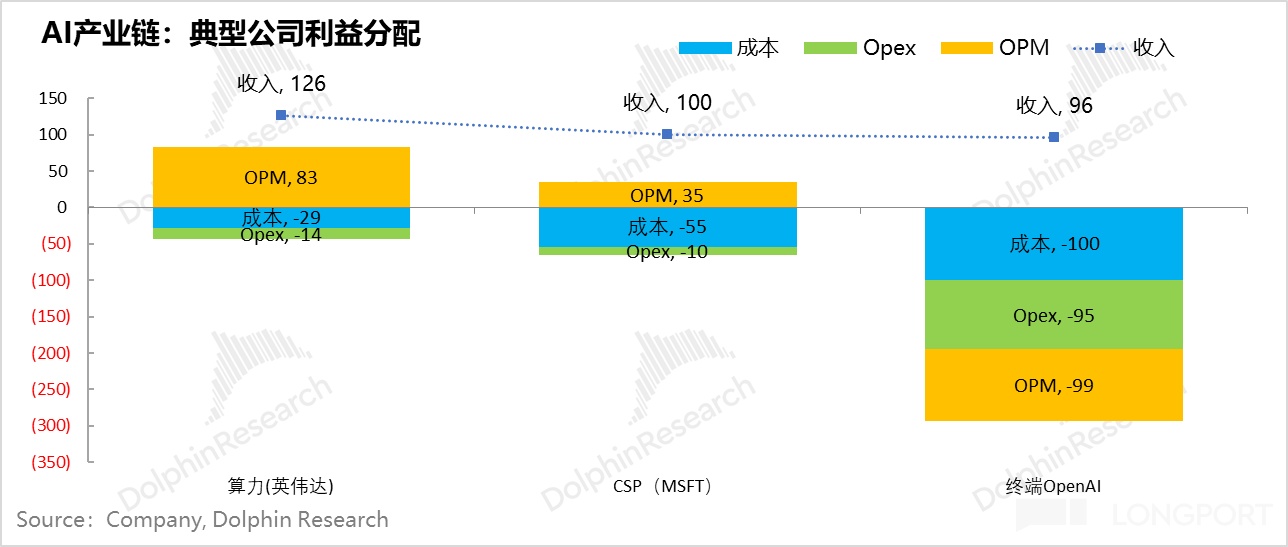
① 算力提供商 (英伟达)——盆满钵满的设备股
云服务的成本,是英伟达的收入。每 100 元的云服务收入,因为有 35 元是设备折旧,按五年折旧期,提供这些服务需要提前采购大约 175 元的设备。
英伟达的 GPU 在采购中的价值大约占到了 70%,相当于云服务这 100 元的收入,单独向英伟达就已支付了 125 元的 GPU 设备采购费。
很显然,作为云服务商生产资料要素采购中,单体价值最大的一环,英伟达在早期 AI 基建期赚得盆满钵满。
② 眼下的 Open AI——8 亿 WAU,但亏光裤子的应用股
整个产业链条中,云服务的需求侧——OpenAI 是需求的源头,它的偿付能力决定了这个链条循环的健康度。但目前 OAI 的创收能力来看,砸了这么多的算力资源,结果上只能算是“金铲子” 挖 “土”。
首先云服务商 100 元的 GPU 租赁收入,到 OpenAI 这里,其实就是它为自己的用户提供服务的云服务成本。按媒体披露的 OpenAI 25 年上半年财务状况,100 元的云开支,只能对应公司 96 元的收入,同时算上公司的研发人员开支、营销和管理支出(不含期权激励)——100 元支出,公司基本亏掉了 100 元。
C. 核心矛盾: 产业链利润分配严重扭曲
把这三家公司简单模拟的经济账放在一起,一幅对比鲜明的产业链利润分配图景就出现了:产业链核心链主的产业链利润、风险收益分配极度不均衡。
上游铲子股——以英伟达为代表的算力资产是轻资产业务,凭借垄断地位,不仅收入增长快,而且应收款风险较低,盈利质量高,盈利赚得盆满钵满;
中游资源整合方——云服务商们承担着大块头的产业链投入,和资源整合,前期投入巨大,明面赚钱但实际现金流吃紧,是事实上最大风险承担方;
下游应用商——生产资料(云服务)太贵,收入太少,只能覆盖一定点的云服务成本,是亏在明面上的应用股,最终应用股的健康程度,才是决定产业链健康度的生死劫。
这样的产业链利益不断往上游转移,AI 主产业链链主们的矛盾日益突出,行业竞争动态天平开始明显变化:
① 算力——英伟达
英伟达凭借第三方 GPU 的垄断地位,尤其是训练阶段的独特优势,享受了 AI 基建早期的最大红利。但它的产品卖到客户那里不是易耗品,而是一个能够使用多年的资本品。
它的高成长,从行业 Beta 角度,主要集中在 AI 数据中心的产能投建期。公司的增长斜率会高度依赖云服务商的资本开支增长斜率,当云服务商的资本开支即使在新高的位置一旦稳定下来,不再告诉增长,那么对应的芯片商收入零增长,万一错估了周期,再来点存货减值,利润率就会直线下滑。
最新季度,英伟达前四大客户贡献了公司 61% 的收入,很显然它的收入就是云服务商们的资本开支预算。
来源:英伟达 2025 年 NDR 材料
当下在 4-5 万亿的市值压力之下,英伟达是持续交付芯片,撑起美股半边天的压力,因此,它的核心诉求就是继续卖芯片,卖出更多芯片,方法上比如说:
a.芯片销售扩散到海外市场,比如特朗普带着 GPU 商家们去中东等地区签单;同时痛失中国市场,让黄仁勋说出了美国要输掉 AI 战争的丧气话。
b. 疯狂迭代:创造云服务商们一直需要更新设备的需求。目前英伟达基本每 2-3 年就会有一次大的产品系列迭代,有些版本的迭代,甚至需要全新的数据中心建设标准来配置 GPU。
② 云服务商——微软:垂直一体化降本
云服务商目前是供不用求,似乎享受的行业红利,但其实长期是承担了产能错配的风险,因为最大的资本开支都是由它来承担的,一旦需求判断失误,数据中心闲置,云服务商就成了损失最为惨重的产业链环节。具体来看,
a. 短期:云服务毛利率更低
当下的短期问题是,由于 GPU 太贵,GPU 云服务比传统云服务毛利率更低。而按照微软 CEO 纳德拉的说法,目前 AI 云业务中产生利润的不是 GPU,而是除了 GPU 之外的其他设备部署(存储、网络、带宽等)——换句话说,现在的 AI 数据中心,因为 GPU 太贵了,其实是用 GPU 引流,靠搭售附加产品来赚钱。
b: AI 算力的摊销折旧风险
运营商生意是重资产业务,最怕生产资料投入的摊销折旧周期太短(风能发电厂和 3G 时代的电信运营商都有过类似问题);英伟达推新太快(两年一次),折旧年限至关重要;
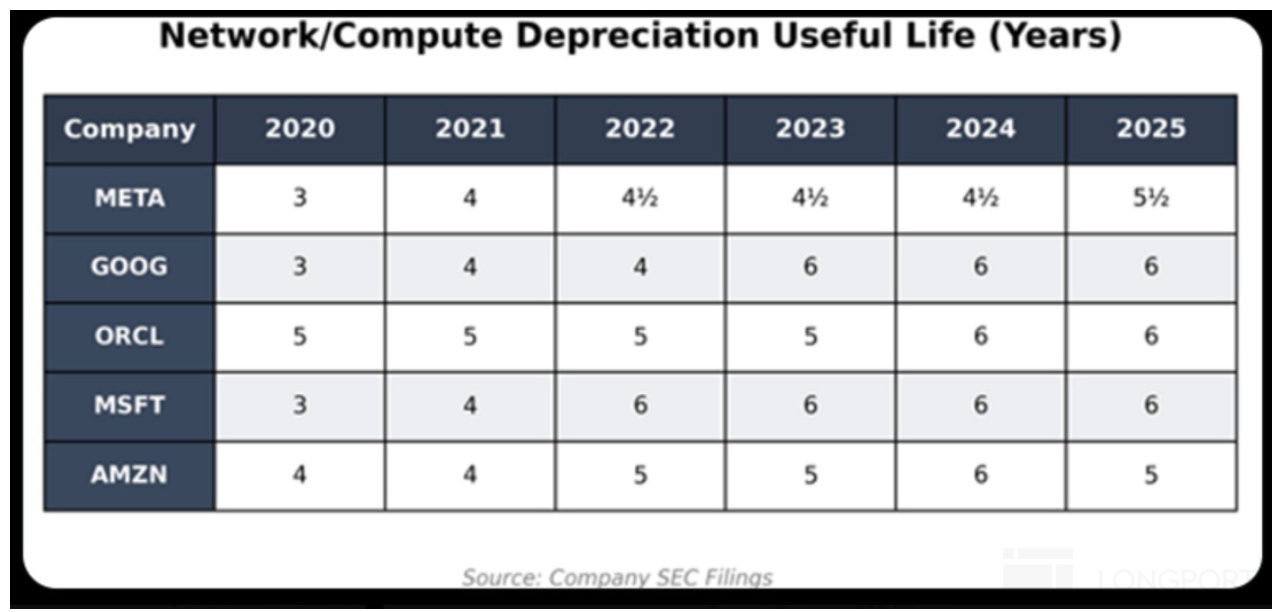
c. 前置投资风险
长期承担了资源整合和资金风险(资本开支);如果客户盈利能力不足、场景落地慢、技术迭代突然出现非线性迭代(比如模型变轻,小模型在端侧能完成 AI 大任务,或者本身软件迭代对算力需求大幅减少),可能后续产能利用不足,导致云服务商产能与需求误判,那么它会成为最大下游客户失败的风险承担方,体现不是应用账款收不会,而是数据中心产能浪费。
很明显,从云服务商的角度,可以做的是,降低数据中心的最大成本项——GPU 成本,比如说绕过英伟达税,自研 1P 算力芯片;虽然需要外包一部分设计工作给到博通、Marvell 等 ASIC 设计商等等,但整体能够大幅降本。结合资料信息,构建 1GW 算力中心,用英伟达 GPU 的成本是 500 亿美金,而用 TPU 大约是 200-300 亿美金。
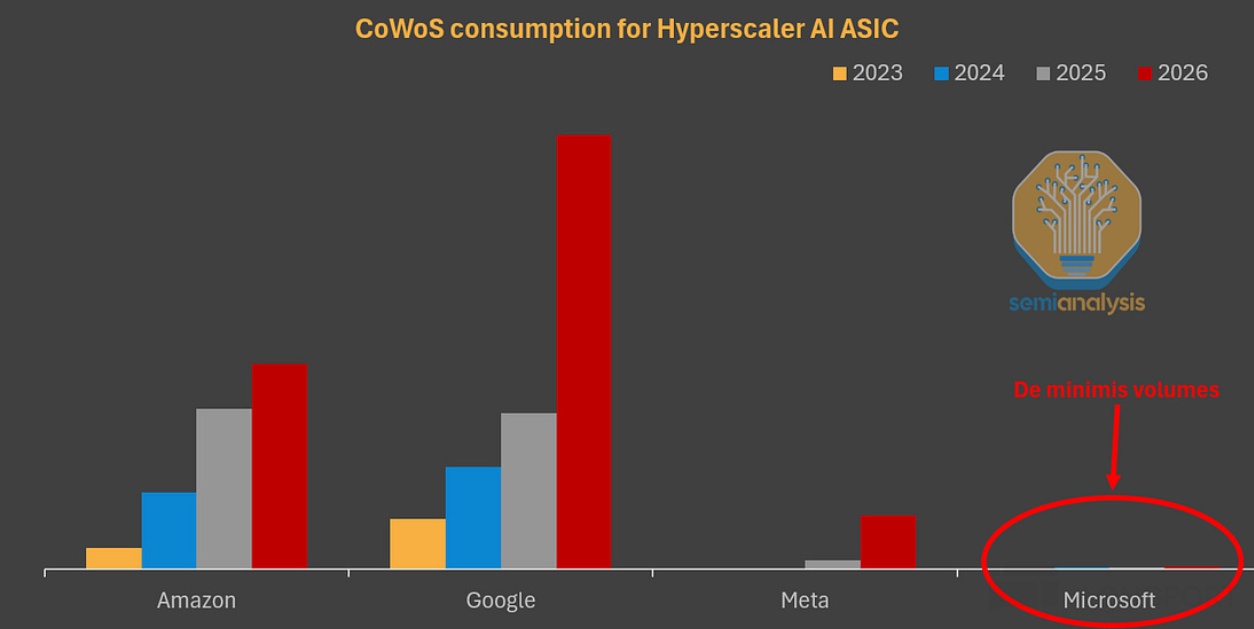
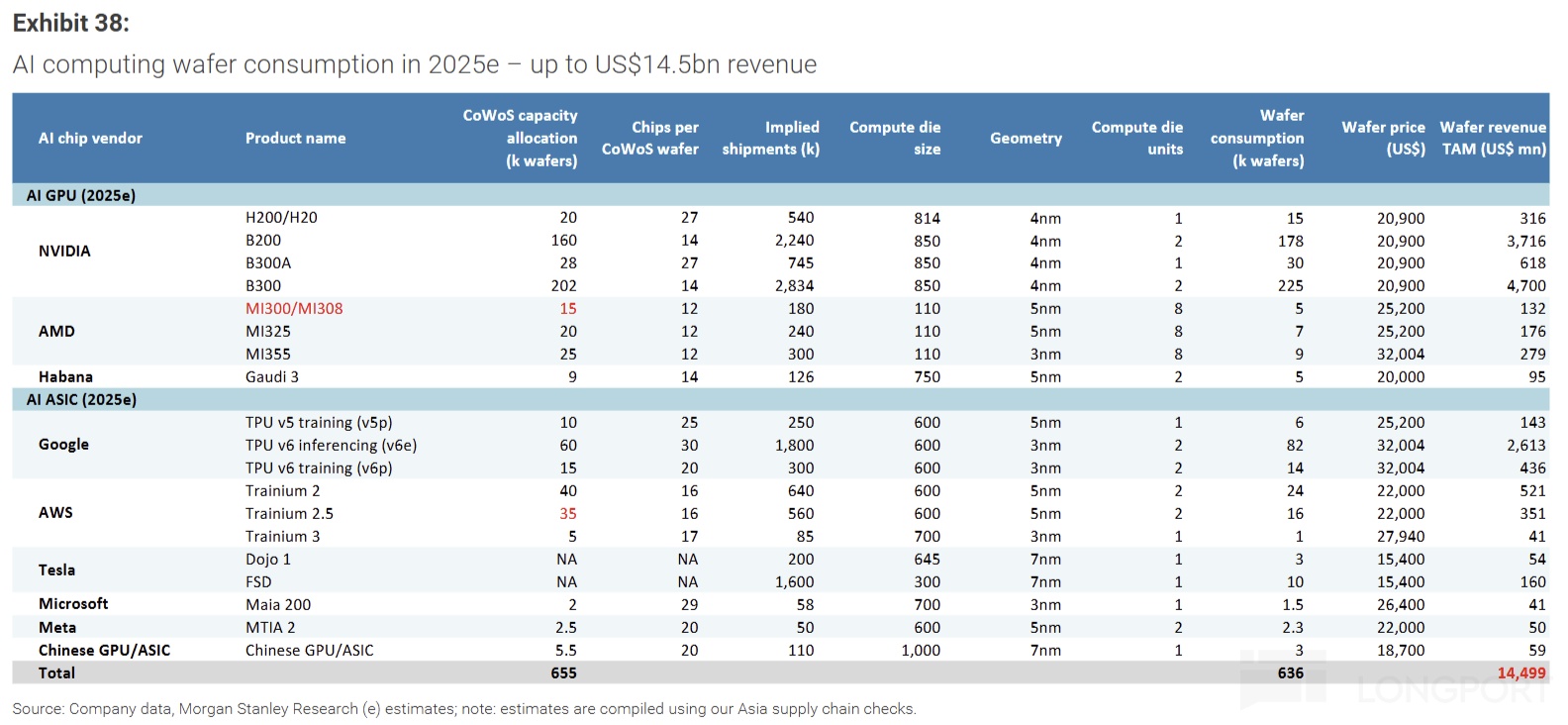
③下游应用(含模型)主要风险——生产资料成本太高,收入不匹配,现金流断裂风险。
这里选 OpenAI 作用终端的场景应用股(含了模型层)。
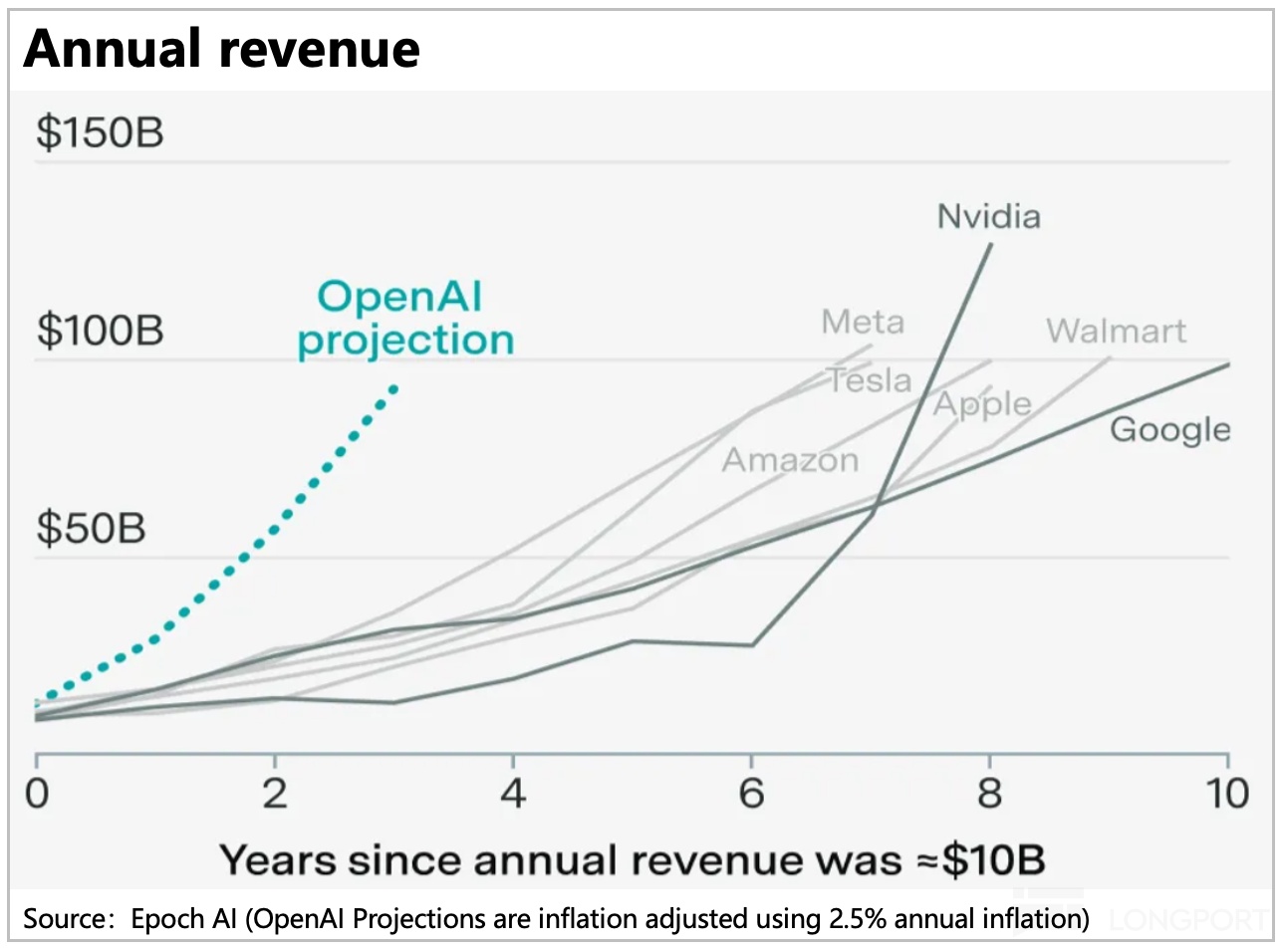
收入高速增长:根据媒体披露,按 OpenAI 目前的月收入推进速度, 2025 年按月预计年底年化200 亿美金,25 全年 130 亿美金,同比增长 250%;
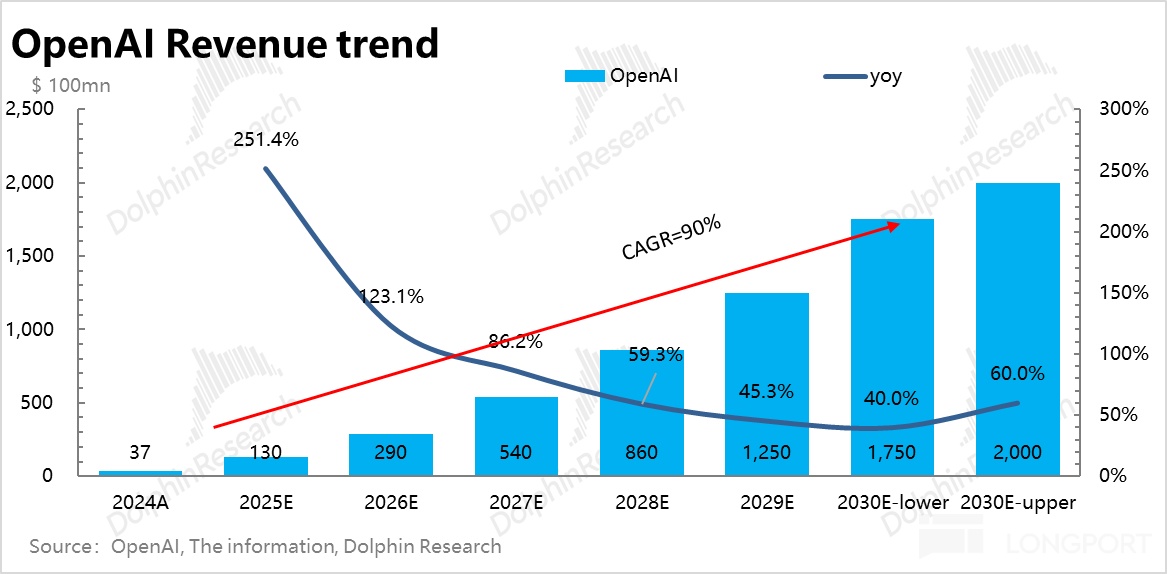
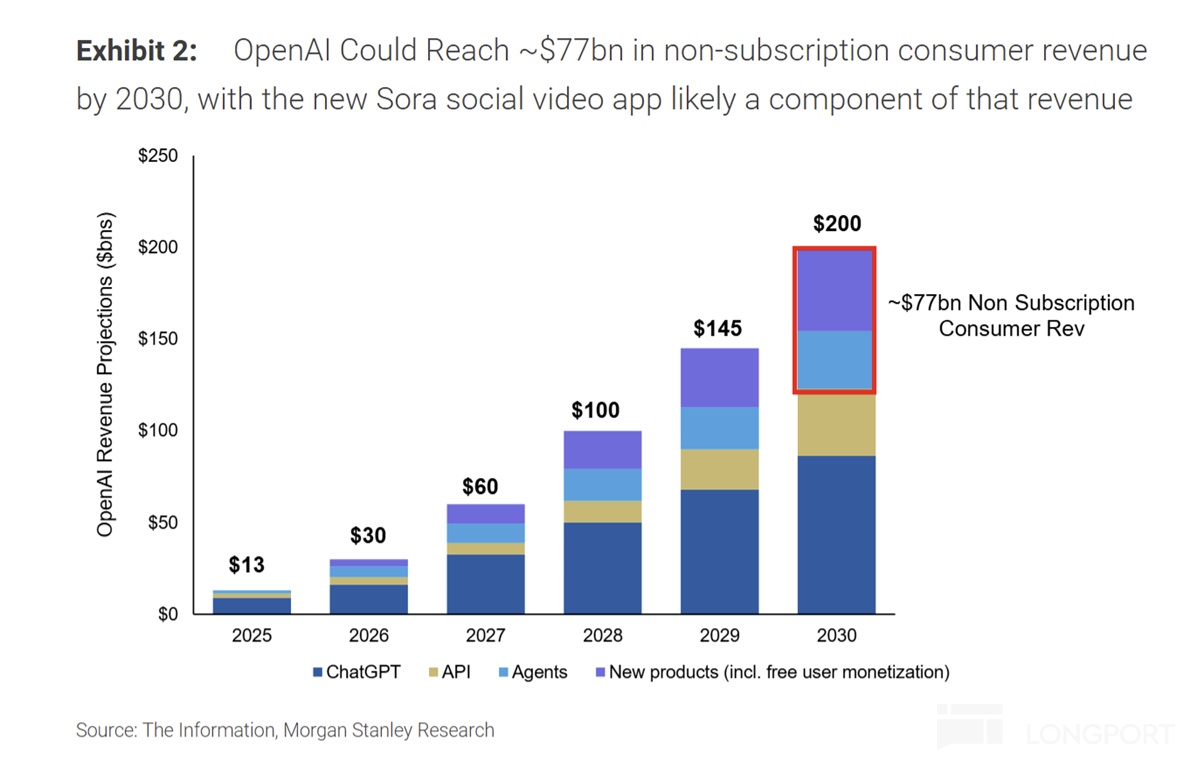
支出飙升更快:这里的问题是,收入在高速增长过程中,并没有正常商业模式下收入放大之后,亏损率逐步减少的情况,反而支出的增长斜率比收入的增长斜率更高,收入越做大,亏损反而约高。
按媒体披露信息,2025 年收入 130 亿,亏损应该估计至少 150 亿上下;如按微软财报信息(按 40% 股权),OpenAI 亏损年化亏损应该已超 300 亿。
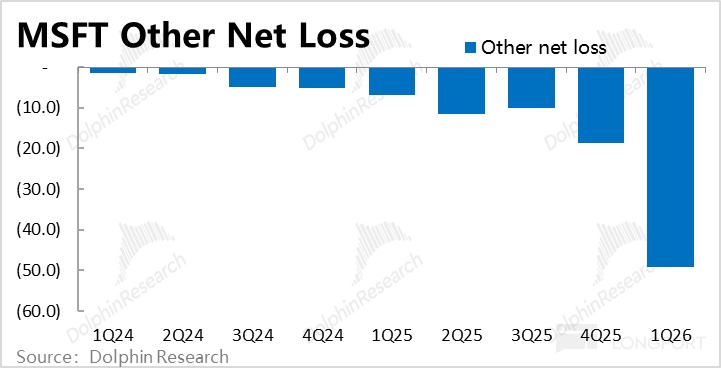
OpenAI 目前的诉求也很明显,首先云服务成本太高了,导致收入不经济,收入多了,反而亏得更凶猛;在与此同时;由于收入缺口太大,公司需要融资的同时,还需要进一步做大收入,而在做大收入过程中,云服务靠外部提供,供应商容量不够,导致产品推新延迟(比如说 Sora 因此推迟,OpenAI Pulse 高定价拖累渗透率)。
三、AI 产业链:巨头博弈产业链定价权
AI 技术(模型)迭代足够快,逐步成熟到可以落地的程度,但部署上成本太高——云服务成本太高,无法支撑技术在应用场景上的快速扩展。
而以上的经济账模拟,可以很清晰地看到,高成本是因为产业链加价太严重——英伟达芯片毛利率 75%(加价率 4 倍)、CSP(云服务) 毛利率 50% 上下(加价率 2 倍),到 OpenAI 使用的时候,铲子的成本已经太高,即使是互联网历史上增速斜率比较高的应用,都无法覆盖更快速度的成本上升。
于是产业链博弈开始了!
英伟达因在数据中心中的价值量和技术壁垒都较高,因此想掏空云服务商的价值,让它沦为 GPU 的包工头。而云服务商觉得英伟达税收得离谱,想要通过自研芯片把英伟达超额利润打掉。
而自从微软解绑了它只能使用 Azure 作为云服务提供商的禁制之后,OpenAI 已经明确表达的自己的意图,要自建数据中心,OpenAI 似乎想消除上游每一段的超额溢价,最好把算力的价格打到白菜价,推动应用的繁荣。
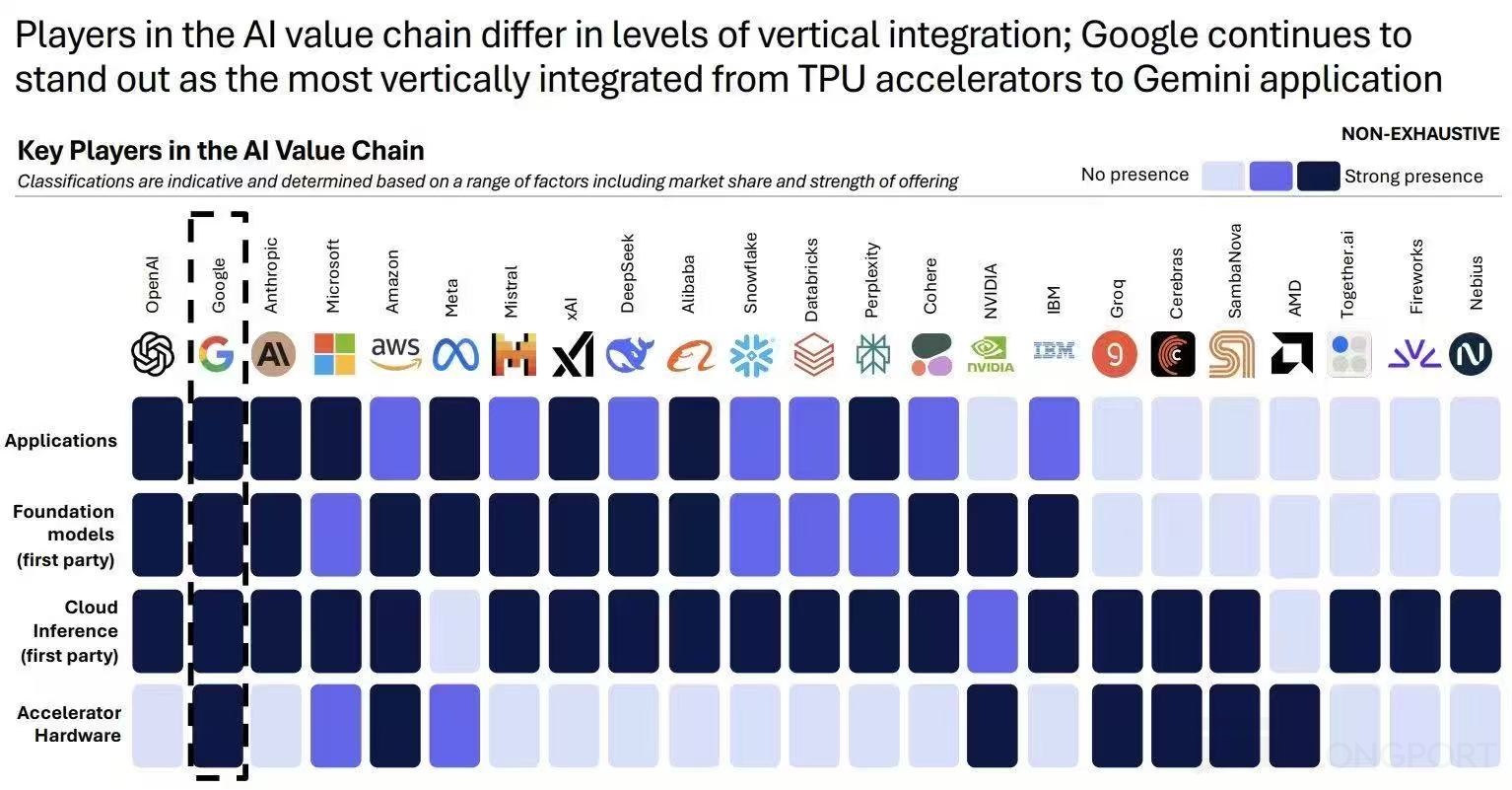
结果就出现了 2025 年年底最受宠的商业模式,也是目前最流行的投资赛道 “全栈 AI”,其实说白了,就是产业链的垂直一体化。三家虽然操作不同,但本质上都是在垂直一体化的方向上努力:
① 英伟达:英伟达 + 新云小弟们=削弱 CSP 大厂产业地位
依赖 GPU 的垄断地位,通过优先供应最新 Rack 系统,产能回购协议等,扶持一堆 IaaS 仰仗英伟达的发货排序的新兴云平台 Coreweave、Nebius 等,其中对 Coreweave 的回购兜底最为突出。
这些新云前期普遍大量融资,新云大多依赖于英伟达的供货倾斜或者融资支持,最终新云的产能基本都是使用英伟达的芯片。通过这个操作,英伟达实际上等于除大型 CSP 之外,锁死了其他小云服务商的 GPU 选择权。
但对于这个操作,微软 CEO 纳德拉层在访谈中曾间接表达过,“一些人以为提供云服务,就是买一堆服务器,插上电就可以了”。言外之意,实际云服务是一个非常复杂的业务,门槛并不低,不然全球的云服务市场那么大,但只是被三四朵云所垄断。
从这个角度出发,今年爆炒的新云服务商,其实背后一定程度上就是在 GPU 供给紧缺的情况下,英伟达通过优先分配权拉起来的下游代理商(二道贩子),假如长期产业供需均衡,产业竞争逻辑走向正常的技术、资金、渠道、规模导向型商业模式,这些新云是不是还能存在,还很难说。
似乎 AI 新云玩家,看起来更像是一个 AI 基建上半场的产业链博弈中的过程产物,而非供需平衡下终局格局中可以和云服务巨头分庭抗礼的竞争对手。
② 云服务商:云服务商 +ASIC 设计商 + 下游产品=削弱英伟达芯片垄断溢价
a. 目前 GPU 用量较大的公司基本都开启了自研芯片的努力,这里除了云服务商$谷歌-C(GOOG.US) 、微软和亚马逊$亚马逊(AMZN.US) ,一些单体用量较大的下游客户如 Meta、字节、特斯拉等都在自研 ASIC 芯片。
在 ASIC 芯片自研子产业链中,ASIC 设计外包商如$博通(AVGO.US) 、$迈威尔科技(MRVL.US) 、、AUC、联发科等等,都是高价值的资产。
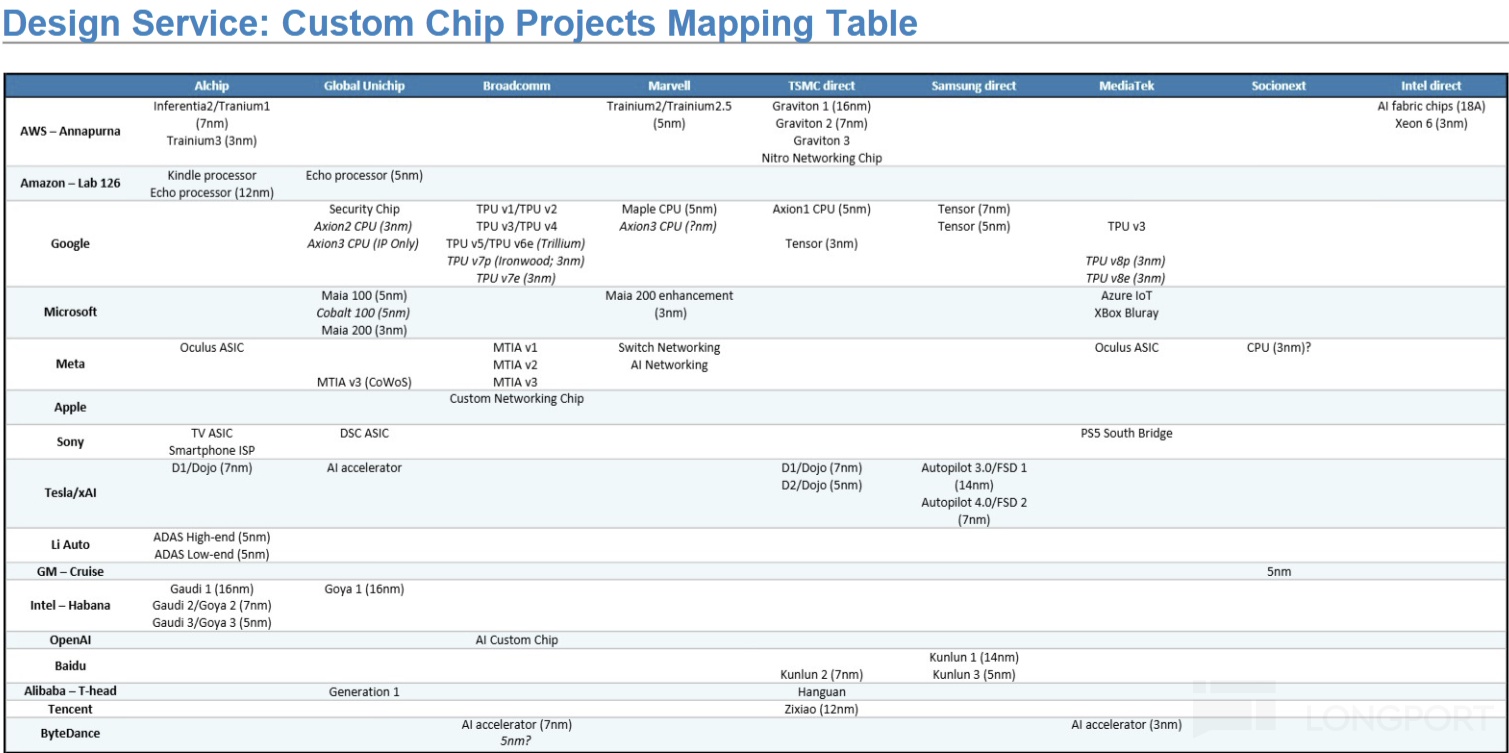
b.讨价还价的二供备胎价值
自研芯片,启动最早,产品名声最高的主要是谷歌联合博通研发的 TPU,直接供应了 Gemini 3 的研发;同时,其实亚马逊也很早启动了自研 GPU 的研发(训练 Trainium、推理 Inferentia)。
按此次英伟达的财报(Anthropic 首次开始使用英伟达合作),Anthropic 模型的研发其实应该主要是基于亚马逊的云和亚马逊的 Trainium 芯片。
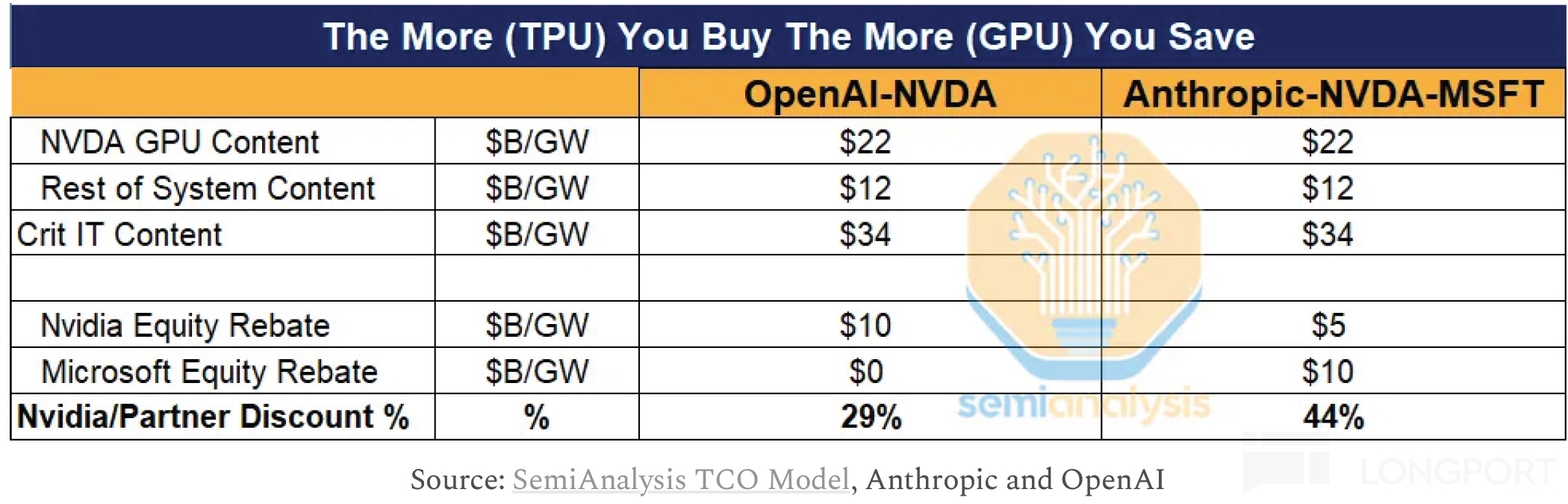
全球两个性能靠前的模型 Gemini 和 Anthropic,一个在完全不用英伟达,一个较少用量的情况下,都把模型训练到了领先的位置,已经明显开始影响到英伟达的在算力行业的定价权。
这样的案例影响下,下游客户通过威胁使用 TPU(甚至都未必是真部署),就能迫使英伟达为锁死下游客户订单,通过融资担保、股权融资、剩余产能兜底等方式来间接降价,本质上就是客户把部署 GPU 的成本给拉了下来。
这些已经是英伟达算力地位受到威胁的实际体现。
c. 下游产品渗透:产品线全系 AI 武装,防守 Chatgpt 崛起
这些处于中间环节的云厂商,本身核心业务大多为再往下游的模型和软件应用的场景,除了往上通过垂直一体化防止英伟达在云业务上偷家,往下还要让自己的全系产品场景都武装上 AI,与 ChatGPT 展开竞争,防止被 ChatGPT 颠覆。

③ OpenAI:产业链自主=Stargate
而处在模型厂和应用场景上的新公司 OpenAI,血亏之下,不想受制于巨头,像以自己的影响力,通过融资来自建一个基本自主的产业链,OpenAI 的大致图景是——上游算力自研和外采对半分(AMD 的 6GW 是备胎算力)、中游云服务完全听命于自己,以帮助自己全力保持技术领先,和推广 AI 应用。
a. 自建数据中心:OpenAI+ 融资 + 芯片商 +Oracle=Stargate
从公司的股权架构设计来看,其实 Stargate 就是一个专门服务 OpenAI 算力需求的大块头新兴云公司(10GW 设计产能)。只是 OpenAI 通过最初的投资入股,在 Stargate 公司股权占比 40%,强化对算力基础设施的主导权。
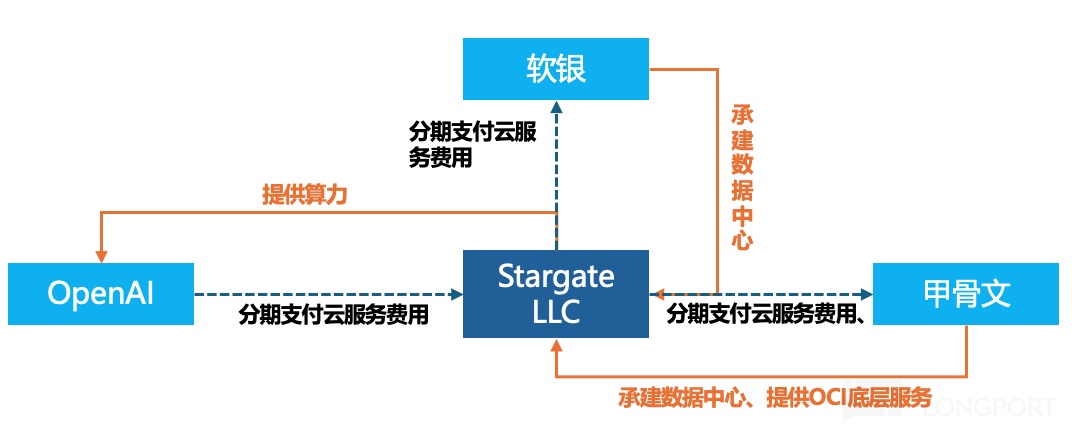
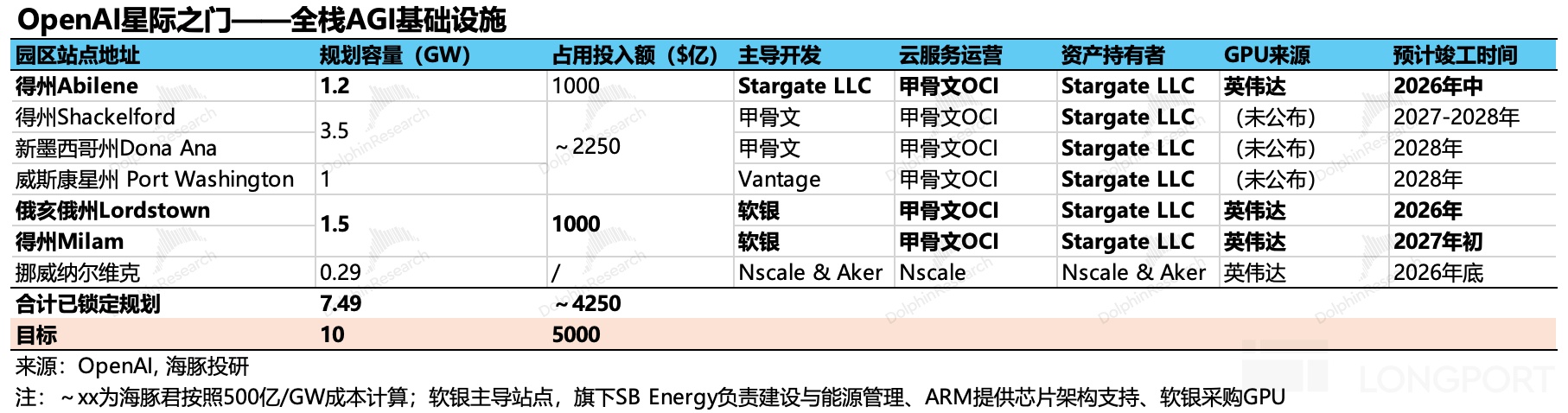
b. 绑定订单:作为一个深受高价算力和供给不足束缚的云服务终端客户,最符合 OpenAI 利益的其实是过剩且便宜的算力,利用上游供应商 FOMO 心理,绑定一切能绑定的产能,用未来的收入预期作为偿付能力,锁定芯片供货。
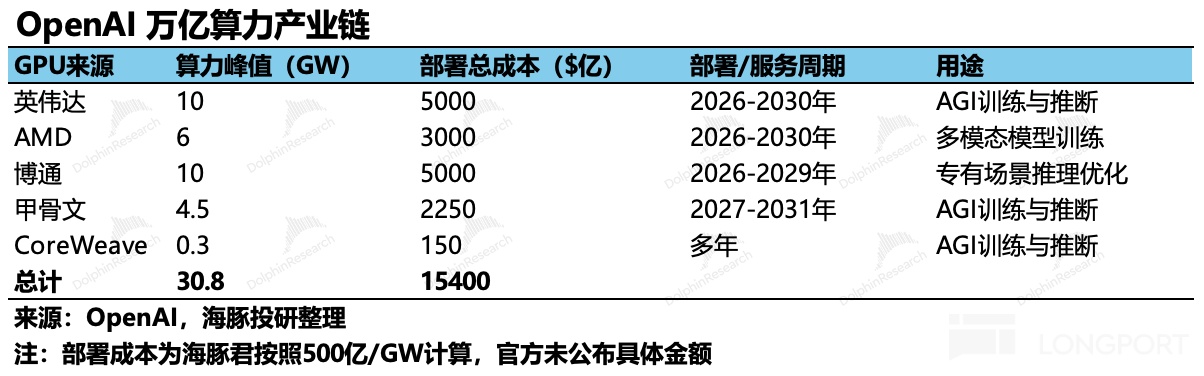
但这里 OpenAI 的收入年化 200 亿要在三年内走到年化 1000 亿美金,才有真正付得起这些付款承诺的可能性。而目前的巨头中没有人在几年内把自己收入打到千亿美金以上。这里海豚君合理推测,它的目的之一可能就是有意制造供给过剩,以便把算力成本打下来。
OpenAI CEO 奥特曼在问到是否会有算力的产能过剩的时候,他毫不隐藏他对算力过剩的渴望:“肯定会有很多轮的算力过剩,无论是 2-3 年内出现,还是 5-6 年内出现,可能是这个时间内多轮的产能过剩。(“there will be come to a glut (of compute) for sure, whether it’s 2-3 or 5-6 years at some point, probably several points along the way.”)
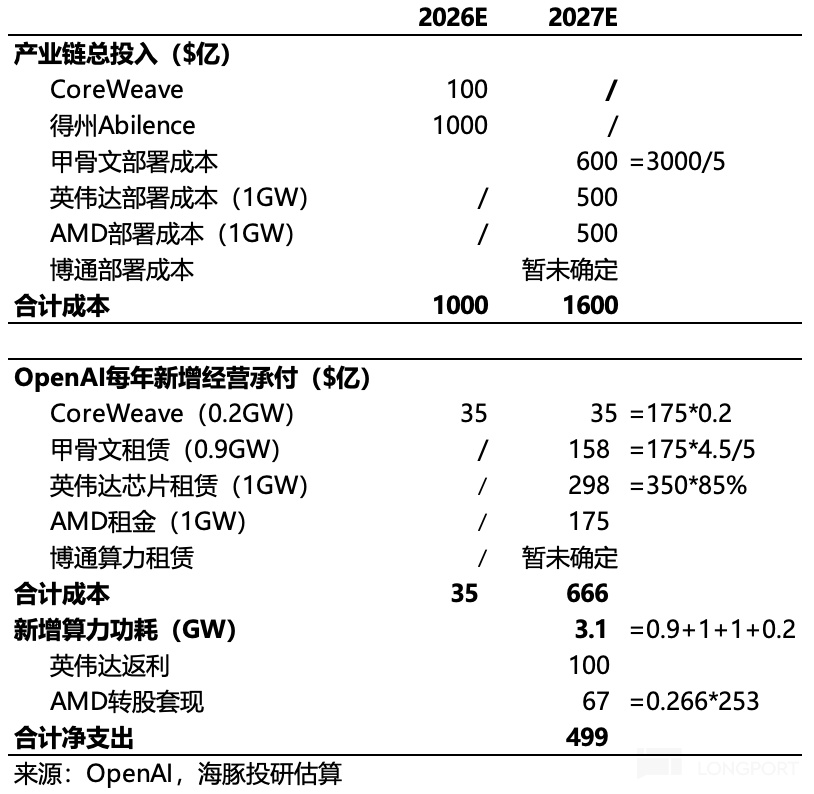
四、总结:2026 年投资主题——算力结构性过剩 + 产业链利润下移?
从以上分析可以看到,目前整个 AI 产业链因为利润过度集中于上游(一定程度上类似新能源车崛起过程中,利润一度高度集中于赣锋和天齐锂业等锂矿股),导致下游现在在做场景应用上,像是用金铲子挖土一样,场景落地的时候,生产资料成本太高,挖出来的东西完全无法匹配这个生产资料的成本。
因此,在当前这种产业链矛盾下,接下来的 AI 投资就是在产业链利润下移 + 结构性供给过剩中找机会,只有算力打下来,才能带动下游的繁荣。
所谓的结构性过剩,比如说传统的电力和机房建设速度跟不上,导致算力吃灰;而产业利润下移,则重点跟踪就是模型在终端场景上的落地速度、对 SaaS 股的可能影响、端侧产品的 AI 渗透、AI 带来的新硬件如机器人与 AI 眼镜等等。
到目前为止,海豚君已经开始看到一些产业链利润下移的迹象,比如现在英伟达的客户可以拿着 TPU 来威胁英伟达给出更优惠的供货条件(其实同样售价下,需要连带股权投资,就是一种间接的产品降价)。
以下,海豚君提供几个可以持续跟踪和验证的判断:
a. 后续的英伟达可能再享受戴维斯双击的机会可能非常小,股价只能靠业绩增长,很难靠估值扩张;这会在不打压台积电逻辑的情况下,单独打压算力估值。
b. 谷歌开始卖裸芯而不是更高利润的 TPU 云租赁的新闻说明了,一方面谷歌在自有芯片的排产上并不是问题(台积电产能安排问题)。
另一方面行业真正紧缺的到 2026 年应该已经转到了 IDC 数据中心的建设上(如数据中心建设的水污染、用电问题等等),而这部分的投资并不是生意壁垒投资,而是产能错配投资。需要时刻关注新开工数据中心的建设节奏。
c. 创业企业:AI 游戏的门槛太高,OpenAI 等新兴公司,想要颠覆巨头并不容易,过度押注 OpenAI 链上的资产并不明智。
因为垂直一体化逻辑的长线条竞争中,还是掌握了资金、算力、模型、云服务和场景的全要素巨头才更容易胜出。
推荐文章





