
Team Google Beats Team OpenAI This Round—What It Means for Your Portfolio
TradingKey - Over the past month, AI-related market flows have diverged. Since the launch of Gemini 3, Alphabet’s stock has rallied sharply—while names tied to OpenAI’s ecosystem have come under pressure. Investors are shifting exposure toward companies aligned with Google, especially Broadcom (AVGO).
Broadcom co-developed Google’s Tensor Processing Units (TPUs), the custom AI chips that power Gemini 3’s training and inference. Alphabet’s ability to bypass NVIDIA’s GPU bottleneck—and fully train Gemini 3 on its own TPU stack—has represented a meaningful challenge to NVIDIA’s dominance in the foundational model space.
Hedge fund Coatue Management reportedly created two comparable portfolios to track the shift. One represents “Team Google,” including Alphabet (GOOGL), Broadcom, Celestica (CLS), Lumentum Holdings (LITE), and TTM Technologies (TTMI). The other represents “Team OpenAI,” consisting of NVIDIA, Microsoft (MSFT), SoftBank Group (SFTBY), Oracle (ORCL), AMD (AMD), and CoreWeave (CRWV).
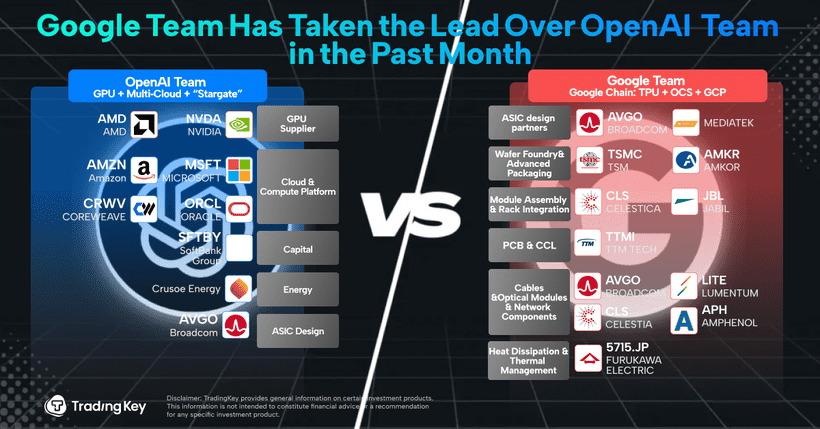
Since late October, returns have sharply diverged. “Team Google” has markedly outperformed, while “Team OpenAI” has lagged.
Goldman Sachs also notes that capital is increasingly rotating into the “Google Chain” narrative—focused on Alphabet’s self-built AI stack—and away from the OpenAI-linked trade once defined by names like Microsoft and Oracle.
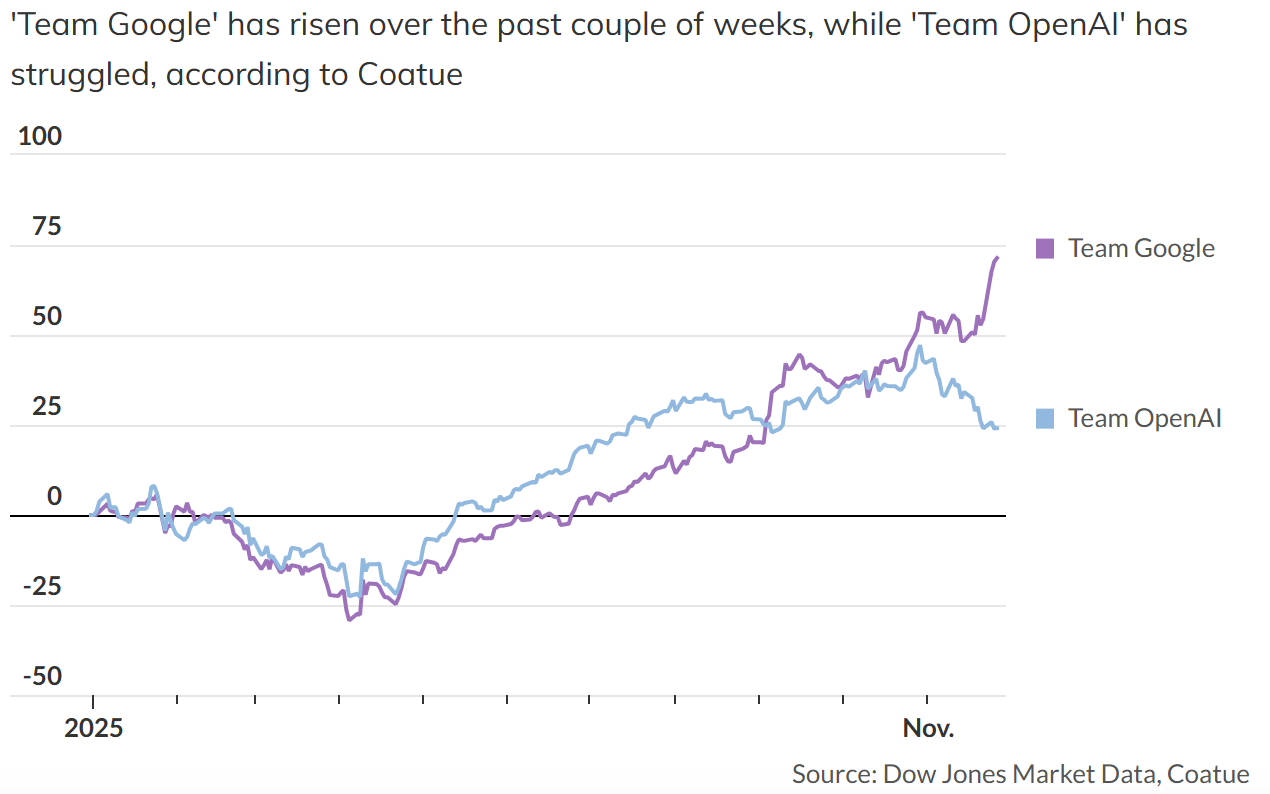
Behind this shift lies a simple readjustment: a renewed bet that Google’s vertically integrated infrastructure—from its TPU hardware to cloud deployments—is more scalable, more independent, and, over time, more profitable.
OpenAI Retreats to Its Core
Faced with growing competitive pressure, OpenAI is refocusing.
In a company-wide note released Monday, CEO Sam Altman wrote: “We are at a critical time for ChatGPT.” He asked teams to prioritize core product execution—specifically refining ChatGPT’s speed, stability, and personalization.
According to the Financial Times, downloads for Gemini 3 are rapidly catching up with ChatGPT. Industry benchmarks also show Gemini 3 outperforming GPT-5 across a range of evaluation tasks.
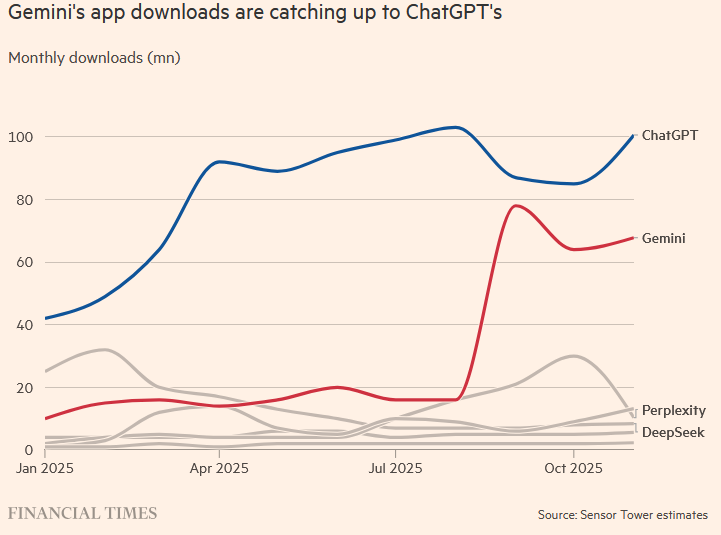
Unlike Alphabet, OpenAI relies on external capital. Its monetization engine is not yet self-sustaining. Internal roadmaps suggest OpenAI would need to scale revenue to ~$200 billion before reaching profitability. While user growth has been impressive—800M weekly actives at peak—sustaining that trajectory while balancing AI safety and UX has proven difficult.
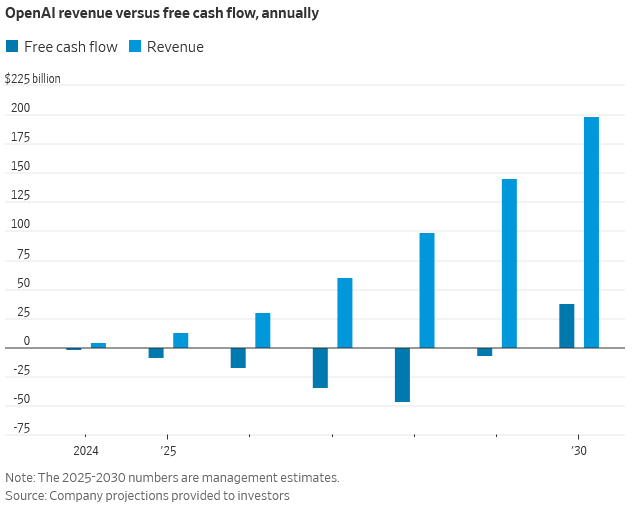
The backlash to GPT-5 was telling: criticized for sounding cold and struggling with basic logic, it highlighted real limits in commercial deployment. Gemini’s arrival has only made the comparison starker. Meanwhile, Anthropic is gaining fast in the enterprise space—adding yet another layer to the pressure.
Meanwhile, one of the most scrutinized capital structures in this cycle has been the OpenAI–Oracle–NVIDIA “loop.”
The Stargate project—a $500 billion hyperscale compute initiative—seeks to build up to 10GW of AI data centers. NVIDIA is both a major supplier and a shareholder in CoreWeave and OpenAI.
The implication is clear: the same capital stack is funding, building, and betting on the outcome. Analysts have described the setup as “a trillion-dollar mega-bet on a single AI outcome.” That scale exceeds normal IT capex cycles by an order of magnitude.
The issue, according to observers: once cash flow realities diverge from expectation, the multiplier effect may run in reverse. Cross-holdings and circular monetization structures magnify risk—but can’t always guarantee returns.
NVIDIA’s Grip Is Tested as Market Reprices the GPU Thesis
Within the OpenAI cluster, NVIDIA (NVDA) has emerged as the most exposed.
Despite strong earnings, its stock has struggled under pressure. The launch of Gemini 3 trained entirely on TPU systems has spurred a collective re-evaluation of NVIDIA’s moat. Alphabet’s ASIC architecture, while less general-purpose than GPU designs, delivers stronger results for inference, cost, and energy efficiency.
More crucially, Google controls the full stack: it builds the chip (TPU), runs the infrastructure (data centers and OCS networks), owns the OS and training tools, and operates the cloud tenant layers (Gemini + Google Cloud). That alignment gives Google both architectural control and cost independence. It’s not just a technical flex—it’s a capital structure victory.
NVIDIA’s fundamentals haven’t deteriorated. But the shift in marginal capital flow reflects investor recalibration. The AI infrastructure story is no longer a GPU-only trade. It’s becoming a multi-architecture game: GPUs and TPUs coexisting. Alphabet, once seen as a second-tier participant in AI infrastructure, is now being priced into the picture as a system-level contender.
Still—one competitive moat remains intact: CUDA.
NVIDIA’s parallel compute ecosystem is often described as the “operating system” for AI development. Just as Windows defined PC-era UX and Linux enabled web servers, CUDA ties together hardware, APIs, and interoperable dev tools that make scaled ML workloads viable out of the box. It remains the connective tissue between labs, enterprises, and developer communities.
But tech analyst Ben Thompson offers a caution. He notes that in the past, hyperscalers like Google and Microsoft broke Intel’s data center dominance by deciding it was “worthwhile” to port infrastructure to multiple CPU types.
He warns: the same may apply to NVIDIA. With AI workloads now concentrated in a handful of cloud providers, those providers have every reason—and every resource base—to dismantle what Thompson calls “the CUDA gate.”
SoftBank: Heavily Tied to OpenAI’s Fate
Another casualty of the recent rerating: SoftBank Group.
Deeply tied to OpenAI’s cap table, it has borne the brunt of volatility. Shares are down ~40% since late October. The reason? Oversized exposure.
SoftBank is on the hook for a $22.5B payment to OpenAI in December—part of a broader $32B commitment. That valuation uplift had propelled its stock upwards in late summer.
Now momentum has turned. If OpenAI were to be valued at $500B, its position would represent over 20% of SoftBank’s net asset value. In bull markets, that’s a boost. But when confidence falters, the exposure cuts both ways.
Investment Insights: GPU vs TPU in a Non‑Zero‑Sum Future
It’s worth noting: GPUs and TPUs are not mutually exclusive.
Long term, AI workloads will likely run on hybrid systems. GPUs remain invaluable for model development, pretraining, prototyping, and multi-purpose research. TPUs excel at inference-scale deployments, powering search, ads, and large-volume model calls with better power and latency characteristics.
In the short run, capital may continue rotating slightly from NVIDIA to Google. That reflects a repricing of TPU commercialization and Google’s hardware suppliers. It also reflects a shift in risk appetite—from scaling bets to cost-efficient ones.
But from a wider lens, compute demand is not slowing—it’s surging.
A functional split between GPUs (for training) and TPUs/ASICs (for inference) may be the most likely outcome. Model builders aren’t choosing sides—they’re optimizing footprints.
Recommended Articles


