
Global AI Models Enter a New Wave of Upgrades Beyond Gemini 3
TradingKey - This month has seen particularly fierce competition in artificial intelligence, with Google's new Tensor Processing Unit (TPU) advancements temporarily distracting the market from AI bubble concerns. However, major AI models globally continued to roll out new versions beyond just Google's Gemini 3.
Foundational Architecture: Gemini 3 Breaks Nvidia Dependency
Undoubtedly, the most anticipated new model in the market is Google's Gemini 3. Its primary breakthrough lies in completely shedding its reliance on Nvidia GPUs for hardware architecture, instead fully adopting Google's proprietary TPUs (Tensor Processing Units).
Gemini 3's upgrade model also marks a significant departure from previous iterations. This time, Google did not merely "fine-tune" or "iterate" on existing infrastructure but fundamentally overhauled its underlying architecture.
In terms of model training processes, Gemini 3 also diverges from traditional large models — such as the GPT series and Llama, which typically depend on a single, massive GPU cluster, extensive text pre-training, and limited human instruction fine-tuning. Google has introduced an entirely new "Mixture-of-Experts (MoE)" architecture: each task is automatically assigned to the most suitable sub-network (expert) for processing, thereby significantly enhancing training specificity and computational efficiency.
Essentially, Gemini 3 operates more like a hybrid system that integrates foundational learning, specialized division of labor, and practical application. By combining its self-developed TPU hardware with distributed parallel algorithms, Google has successfully propelled AI models into a "general intelligence" phase closer to real-world applications, moving beyond the compute-heavy, brute-force training methods of previous large models.
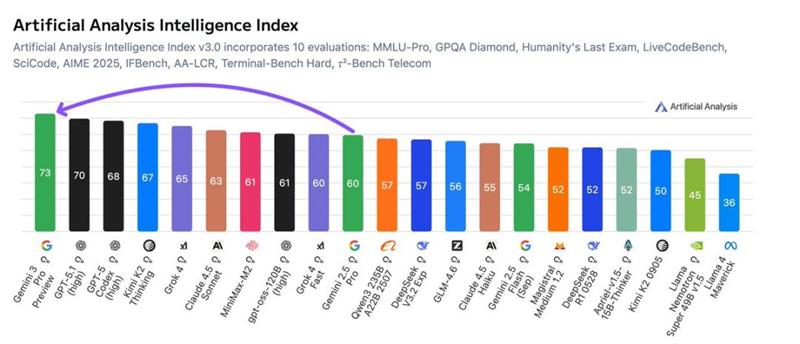
According to the latest comprehensive ratings from independent firm Artificial Analysis, Gemini 3 Pro ranks first with a significant lead, outperforming GPT-5.1 by 3 points. This marks the first time Google has topped global rankings with such a decisive advantage since entering the language model domain, effectively breaking OpenAI's long-standing myth of leadership.
 Model Layer: Anthropic's Claude Opus 4.5 Emerges Powerfully
Model Layer: Anthropic's Claude Opus 4.5 Emerges Powerfully
Anthropic, widely regarded as the most formidable competitor to OpenAI and Google, recently released the latest version of its flagship AI model, Claude Opus 4.5.
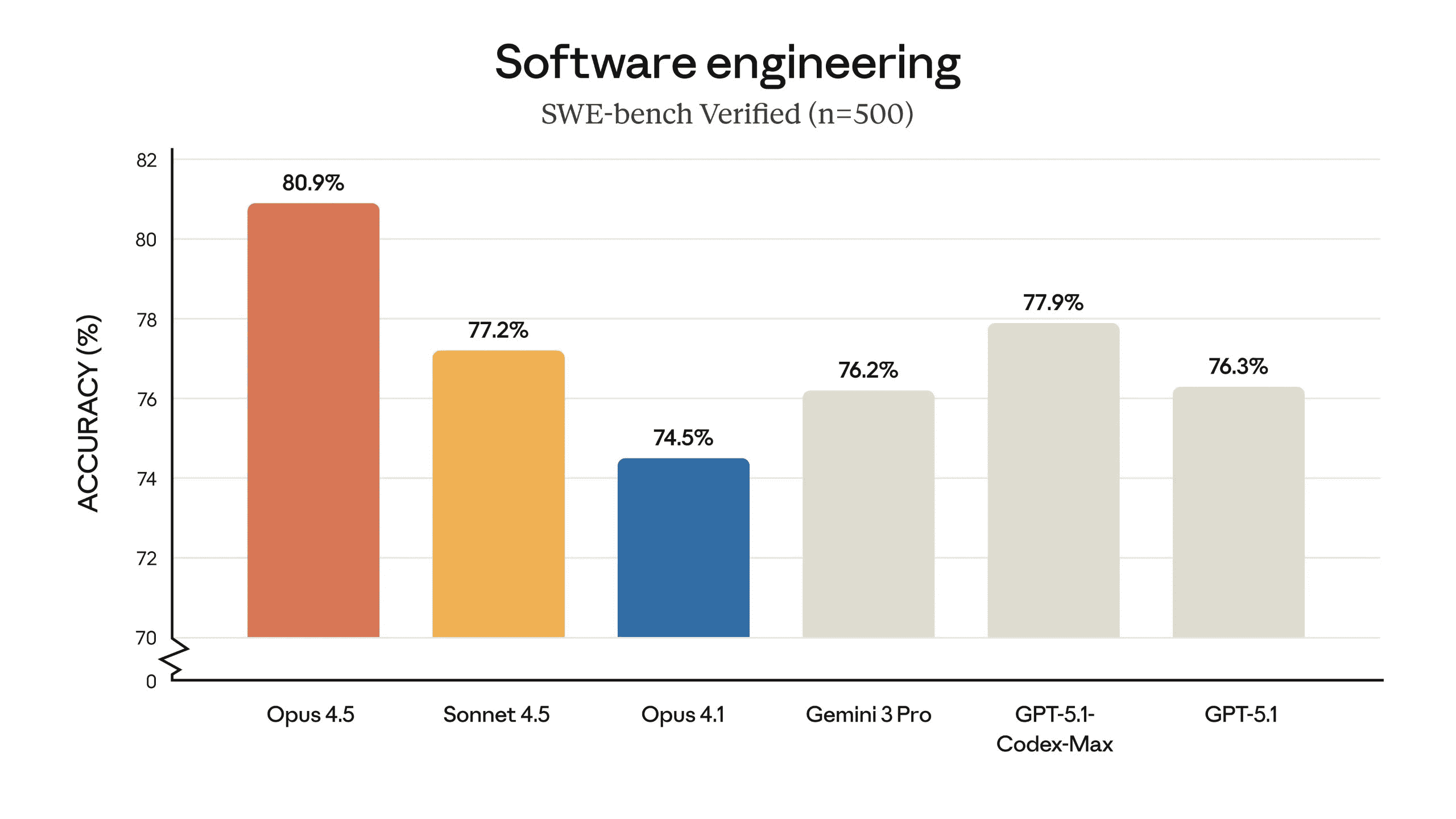
Official descriptions state that the new model performs "markedly stronger" in executing everyday tasks. Notably, Claude Opus 4.5 has achieved industry-leading standards in "Agentic Coding." Based on results from the SWE-Bench Verified software capability benchmark suite, its score surpassed both Gemini 3 Pro and GPT-5.1.
Unlike OpenAI, Anthropic has not invested heavily in compute-intensive areas like image or video generation. Instead, it has focused on optimizing coding capabilities and enterprise automation deployment, with particular emphasis on practical applicability in program compilation, integration, and task execution, rather than human-computer interaction dialogue features. Currently, the company provides services to over 300,000 enterprise users.
Anthropic has become an undeniable force in the AI programming ecosystem. Last week,Microsoft andNvidia jointly announced multi-billion dollar investments in Anthropic, which propelled its valuation to approximately $350 billion. The most notable aspect of their partnership agreement is that Microsoft Azure AI Foundry customers will gain direct access to the Claude series of models. This makes Claude the only cutting-edge large model simultaneously deployed across the three major cloud platforms (Azure, AWS, and Google Cloud).
Notably, Anthropic is also significantly expanding its use of TPUs. Reports indicate that the company signed a multi-billion dollar long-term cloud partnership agreement, committing to use up to "one million TPUs" in the future, with a total value potentially reaching "tens of billions of dollars." This not only reflects its computing power partnership with Google but also suggests that leading external AI developers broadly recognize the performance and cost advantages of Google's TPUs.
According to a July report from Menlo Ventures, Anthropic ranks first in enterprise AI adoption with a 32% market share; OpenAI follows with 25% (nearly halved from two years ago), Google holds 20%, and Meta 9%.
Application Layer: OpenAI's GPT-5.1 Strengthens Ecosystem Strategy
For an extended period, OpenAI has consistently held the title of the industry's "smartest model." Its vision is to create Artificial General Intelligence (AGI) that benefits all humanity, and it has pursued an expansive and comprehensive strategic roadmap to solidify its industry dominance, featuring a broader product portfolio and larger organizational structure.
On November 22nd, OpenAI officially released GPT-5.1. Seasoned AI users widely consider this version to be "markedly smarter" than its predecessor.
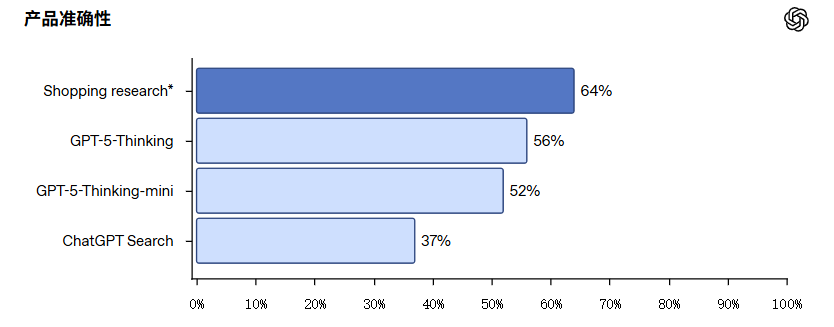
To meet peak demand for the holiday shopping season, OpenAI also launched a free AI shopping search feature this Monday, aiming to integrate chat models into the consumer shopping journey and thereby create new commercialization scenarios.
The official blog noted that this feature is optimized based on the GPT-5-Thinking-Mini model, which gathers user preferences through a Q&A format and then gradually recommends 10 to 15 items for selection from the web.
Over the past few weeks, OpenAI has intensively updated its products, including group chat features, a free version of ChatGPT for K-12 educators in the U.S., and a browser version with ChatGPT built-in. This indicates the company is actively expanding its user base and application scenarios to address growth pressures and strengthen its platform ecosystem.
Chinese LLM: Alibaba's Qwen 3 Max Also Shines
China's AI sector has also achieved breakthroughs. On November 24th,Alibaba unveiled its next-generation AI trading model, Qwen 3 Max (Tongyi Qianwen 3 Max).
Within just one week of its public beta launch, the product's downloads surpassed 10 million, setting a new historical record for global AI application downloads. In a short span, Qwen 3 Max outpaced ChatGPT, Sora, and even DeepSeek, which caused a stir earlier this year, becoming the fastest-growing AI product in history.
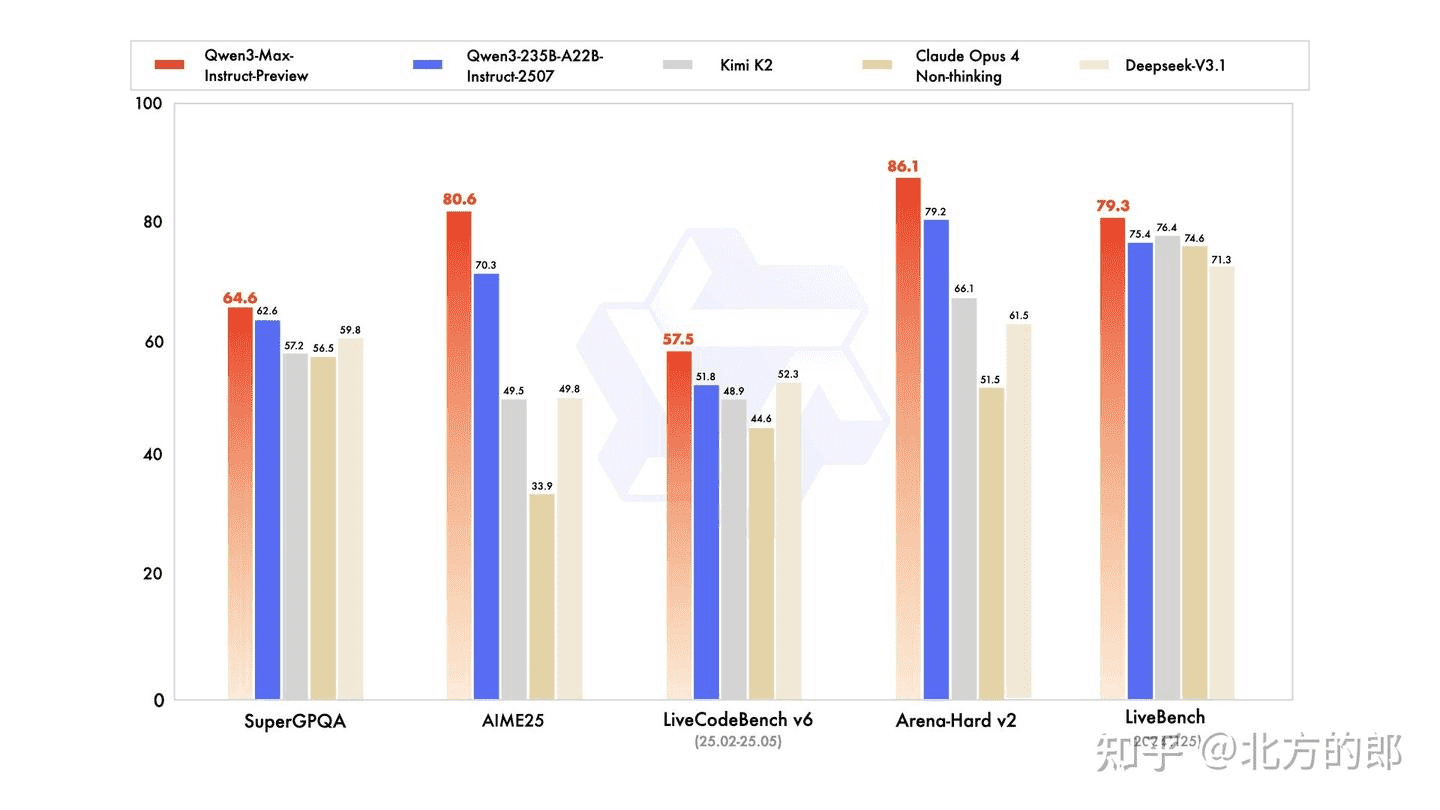
In terms of performance, Qwen 3 Max-Preview set new best records for the Tongyi series across multiple authoritative benchmark suites (MMLU, GSM8K, HumanEval, BIG-Bench Hard, etc.). It even outperformed GPT-5 and Claude Opus 4 on some metrics.
Although Alibaba's core e-commerce business did not perform exceptionally, the market still holds high expectations for these companies, benefiting from a significant surge in its AI cloud business.
From an investment and financial trading perspective, Chinese AI models also demonstrated strong capabilities. In the "Alpha Arena" live trading experiment organized by the Hyperliquid trading platform, each AI model received $10,000 in capital and autonomously traded cryptocurrency perpetual contracts under identical conditions. The results showed DeepSeek secured the top spot with a 57.5% return, while Qwen 3 Max ranked second with a 25% return, executing a total of 36 trades and achieving a Sharpe ratio of 0.328, making it the most stable performer among all participating models.
Qwen 3 Max’s strategy focuses on volatility control and risk balancing, effectively avoiding common issues like "overtrading" and "surging risk" seen in larger models, thus demonstrating exceptional stability and strategic optimization capabilities.
Recommended Articles


